Which is the best book to study Microsoft 70-489 dumps? “Developing Microsoft SharePoint Server 2013 Advanced Solutions” is the name of Microsoft 70-489 exam dumps which covers all the knowledge points of the real Microsoft exam. Valid and updated Microsoft SharePoint applications 70-489 dumps pdf exams video training. Pass4itsure 70-489 dumps exam questions answers are updated (97 Q&As) are verified by experts.
The associated certifications of 70-489 dumps are Microsoft SharePoint Applications. Pass4itsure is a website that provides the counseling courses for IT professionals to participate in Microsoft https://www.pass4itsure.com/70-489.html dumps and help them get the Microsoft 70-489 certification.
Exam Code: 70-489
Exam Name: Developing Microsoft SharePoint Server 2013 Advanced Solutions
Updated: Sep 15, 2017
Q&As: 97
[100% Pass Microsoft 70-489 Dumps From Google Drive]:https://drive.google.com/open?id=0BwxjZr-ZDwwWMVJwQXUxZ0JQV28
[100% Pass Microsoft 70-414 Dumps From Google Drive]:https://drive.google.com/open?id=0BwxjZr-ZDwwWT1R2UXFwcFMwZEE

Pass4itsure Latest and Most Accurate Microsoft 70-489 Dumps Exam Q&AS:
QUESTION 5
You need to ensure that employees can change their display name.
Which object model should you use?
A. Use the server-side object model.
B. Use a Representational State Transfer (REST) based service.
C. Use the JavaScript object model.
D. Use the .Net client-side object model.
070-489 exam Correct Answer: A
Explanation
Explanation/Reference:
QUESTION 6
You need to search for research papers that contain media files 070-489 dumps.
What should you do? {Each correct answer presents part of the solution. Choose all that apply.)
A. Add an Association operation from the research papers.ID field to the Windows Media Service.
B. Use Remote BLOB storage.
C. Add an Association operation from the research papers.ID field to the TreyResearch external content type.
D. Create a SQL Server-based external content type.
Correct Answer: BD
Explanation
Explanation/Reference:
QUESTION 7
You need to configure the Content Enrichment web service to index content from the AbstractIndexer service.
What should you do?
A. Set the value of the OutputProperties array to Trigger=True.
B. Set the value of the SendRawData property to false.
C. Configure conditions for the Trigger property.
D. Set the value of the InputProperties property to Trigger=True.
Correct Answer: A
Explanation
Explanation/Reference:
QUESTION 8
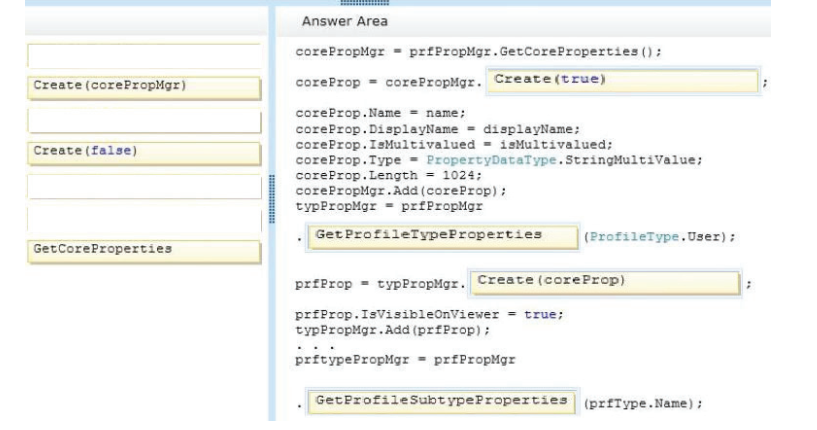
You need to add code to line MP22 to create the custom profile property.
How should you complete the relevant code? (To answer, drag the appropriate code segments to
the correct locations in the answer area. Each code segment may be used once or not at all. You
may need to drag the split bar between panes or scroll to view content.)
Select and Place:
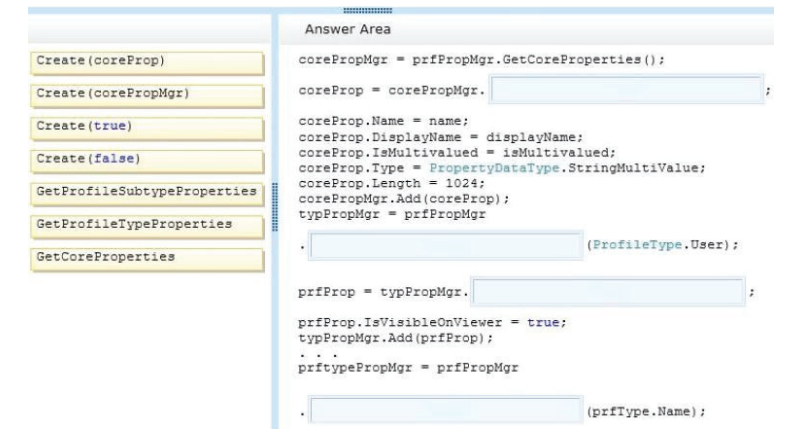
70-489 exam Correct Answer:
Explanation
Explanation/Reference:
QUESTION 9
You need to add code to line MP57 to display the required properties for the user profile.
How should you complete the relevant code? (To answer, drag the appropriate code segments to
the correct locations in the answer area. Each code segment may be used once, more than once,
or not at all. You may need to drag the split bar between panes or scroll to view content.)
Select and Place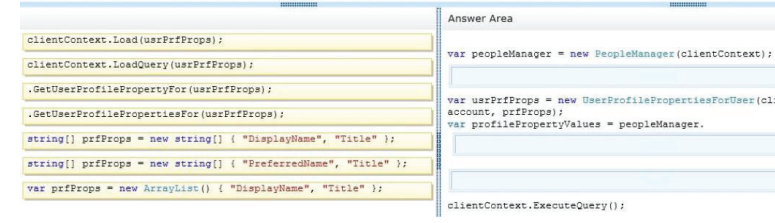
Correct Answer:
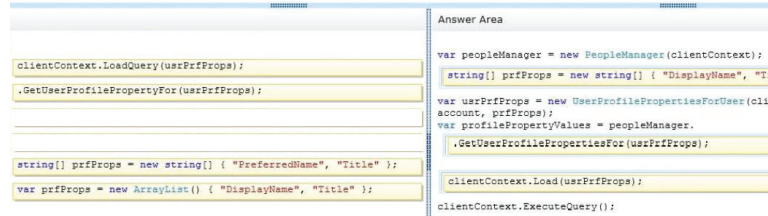
Explanation
Explanation/Reference:
QUESTION NO: 11
Which two updates occur when a client application opens a stream to begin a file write on a cluster
running MapReduce v1 (MRv1)?
A. Once the write stream closes on the DataNode, the DataNode immediately initiates a black
report to the NameNode.
B. The change is written to the NameNode disk.
C. The metadata in the RAM on the NameNode is flushed to disk.
D. The metadata in RAM on the NameNode is a flushed disk.
E. The metadata in RAM on the NameNode is updated.
F. The change is written to the edits file.
70-489 dumps Answer: D,F
Note: Namenode stores modifications to the filesystem as a log appended to a
native filesystem file (edits). When a Namenode starts up, it reads HDFS state from an image file
(image) and then applies edits from the edits log file. It then writes a new HDFS state to (fsimage) and
starts normal operation with an empty edits file. Since namenode merges fsimage and edits files
only during start-up, edits file could get very large over time on a large cluster. Another side effect
of the larger edits file is that the next restart of Namenade takes longer.
The secondary name node merges fsimage and edits log periodically and keeps edits log size within a limit. It is usually run on a different machine than the primary Namenode since its memory
requirements are on the same order as the primary name mode. The secondary name node is
started by bin/start-of.sh on the nodes specified in the conf/masters file.
QUESTION NO: 12
For a MapReduce job, on a cluster running MapReduce v1 (MRv1), what’s the relationship
between tasks and task templates?
A. There are always at least as many task attempts as there are tasks.
B. There are always at most as many task attempts as there are tasks.
C. There are always exactly as many task attempts as there are tasks.
D. The developer sets the number of task attempts on job submission.
Answer: C
QUESTION NO: 13
What action occurs automatically on a cluster when a DataNode is marked as dead?
A. The NameNode forces re-replication of all the blocks which were stored on the dead DataNode.
B. The next time a client submits a job that requires blocks from the dead DataNode, the JobTracker
receives no heartbeats from the DataNode. The JobTracker tells the NameNode that the
DataNode is dead, which triggers block re-replication on the cluster.
C. The replication factor of the files which had blocks stored on the dead DataNode is temporarily
reduced until the dead DataNode is recovered and returned to the cluster.
D. The NameNode informs the client which writes the blocks that are no longer available; the client
then re-writes the blocks to a different DataNode.
070-489 pdf Answer: A
How NameNode Handles data node failures?
NameNode periodically receives a Heartbeat and a Blockreport from each of the DataNodes in the
cluster. Receipt of a Heartbeat implies that the DataNode is functioning properly. A Blockreport
contains a list of all blocks on a DataNode. When NameNode notices that it has not received a
heartbeat message from a data node after a certain amount of time, the data node is marked as
dead. Since blocks will be under replicated the system begins replicating the blocks that were
stored on the dead data node. The NameNode Orchestrates the replication of data blocks from one
data node to another. The replication data transfer happens directly between data nodes and the
data never passes through the name node.
Note: If the Name Node stops receiving heartbeats from a Data Node it presumes it to be dead and
any data it had to be gone as well. Based on the block reports it had been receiving from the dead
node, the Name Node knows which copies of blocks died along with the node and can make the
decision to re-replicate those blocks to other Data Nodes. It will also consult the Rack Awareness
data in order to maintain the two copies in one rack, one copy in another rack replica rule when
deciding which Data Node should receive a new copy of the blocks.
Reference: 24 Interview Questions & Answers for Hadoop MapReduce developers, How
NameNode Handles data node failures’
QUESTION NO: 14
How does the NameNode know DataNodes are available on a cluster running MapReduce v1
(MRv1)
A. DataNodes listed in the dfs.hosts file. The NameNode uses as the definitive list of available
DataNodes.
B. DataNodes heartbeat in the master on a regular basis.
C. The NameNode broadcasts a heartbeat on the network on a regular basis, and DataNodes
respond.
D. The NameNode sends a broadcast across the network when it first starts, and DataNodes
respond.
Answer: B
How NameNode Handles data node failures?
NameNode periodically receives a Heartbeat and a Blockreport from each of the DataNodes in the
cluster. Receipt of a Heartbeat implies that the DataNode is functioning properly. A Blockreport
contains a list of all blocks on a DataNode. When NameNode notices that it has not received a
heartbeat message from a data node after a certain amount of time, the data node is marked as
dead. Since blocks will be under replicated the system 70-489 dumps begins replicating the blocks that were stored on the dead data node. The NameNode Orchestrates the replication of data blocks from one
data node to another. The replication data transfer happens directly between data nodes and the
data never passes through the name node. Reference: 24 Interview Questions & Answers for Hadoop MapReduce developers, How NameNode Handles data node failures?
The courses of Pass4itsure are developed by experienced experts’ extensive experience and expertise and the 70-489 dumps quality is very good and has a very fast update rate. Besides, the exercises we provide are very close to the real https://www.pass4itsure.com/70-489.html exam questions, almost the same.
