
Tag: dp-200 practice test
[2021.3] Prep Actual Microsoft DP-200 Exam Questions For Free Share
Valid Microsoft DP-200 questions shared by Pass4itsure for helping to pass the Microsoft DP-200 exam! Get the newest Pass4itsure Microsoft DP-200 exam dumps with VCE and PDF here: https://www.pass4itsure.com/dp-200.html (227 Q&As Dumps).
[Free PDF] Microsoft DP-200 pdf Q&As https://drive.google.com/file/d/1MsPABHzc7aMSKZ_rHLt5zWq4rkiX8b3C/view?usp=sharing
Suitable for DP-200 complete Microsoft learning pathway
The content is rich and diverse, and learning will not become boring. You can learn in multiple ways through the Microsoft DP-200 exam.
- Download
- Answer practice questions, the actual Microsoft DP-200 test
Microsoft DP-200 Implementing an Azure Data Solution
Free Microsoft DP-200 dumps download
[PDF] Free Microsoft DP-200 dumps pdf download https://drive.google.com/file/d/1MsPABHzc7aMSKZ_rHLt5zWq4rkiX8b3C/view?usp=sharing
Pass4itsure offers the latest Microsoft DP-200 practice test free of charge 1-13
QUESTION 1
You need to ensure that phone-based polling data can be analyzed in the PollingData database.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions
to the answer are and arrange them in the correct order.
Select and Place:
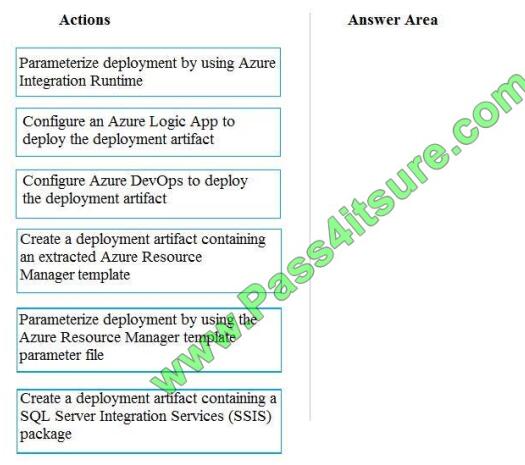
Correct Answer:
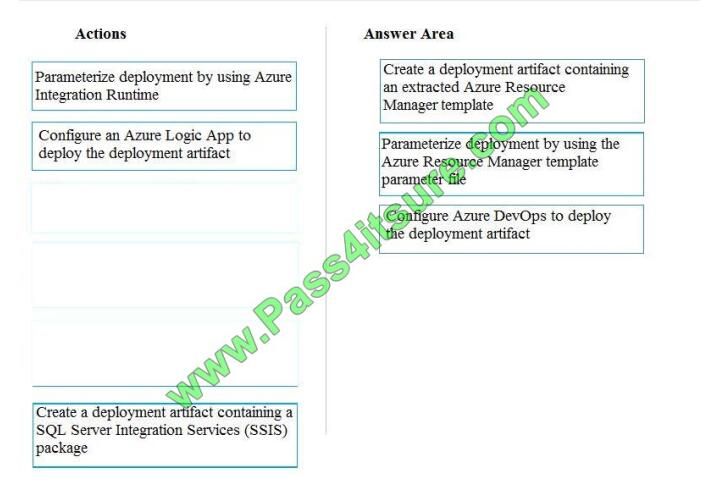
Explanation/Reference:
All deployments must be performed by using Azure DevOps. Deployments must use templates used in multiple
environments No credentials or secrets should be used during deployments
QUESTION 2
You are a data architect. The data engineering team needs to configure a synchronization of data between an onpremises Microsoft SQL Server database to Azure SQL Database.
» Read more about: [2021.3] Prep Actual Microsoft DP-200 Exam Questions For Free Share »
[2021.2] Microsoft DP-200 Exam Prep Actual Dumps Questions For Free Share
Valid Microsoft DP-200 dumps questions shared by Pass4itsure for helping to pass the Microsoft DP-200 exam! Get the newest Pass4itsure Microsoft DP-200 exam dumps with VCE and PDF here: https://www.pass4itsure.com/dp-200.html (227 Q&As Dumps).
Suitable for DP-200 complete Microsoft learning pathway
The content is rich and diverse, and learning will not become boring. You can learn in multiple ways through the Microsoft DP-200 exam.
- Download
- Watch the video
- Answer practice questions, the actual test
DP-200 Implementing an Azure Data Solution
Free Microsoft DP-200 dumps download
[PDF] Free Microsoft DP-200 dumps pdf download https://drive.google.com/file/d/1MsPABHzc7aMSKZ_rHLt5zWq4rkiX8b3C/view?usp=sharing
Pass4itsure offers the latest Microsoft DP-200 practice test free of charge 1-13
QUESTION 1
The data engineering team manages Azure HDInsight clusters. The team spends a large amount of time creating and
destroying clusters daily because most of the data pipeline process runs in minutes.
You need to implement a solution that deploys multiple HDInsight clusters with minimal effort.
What should you implement?
A. Azure Databricks
B. Azure Traffic Manager
C. Azure Resource Manager templates
D. Ambari web user interface
Correct Answer: C
A Resource Manager template makes it easy to create the following resources for your application in a single,
coordinated operation:
HDInsight clusters and their dependent resources (such as the default storage account).
Other resources (such as Azure SQL Database to use Apache Sqoop).
» Read more about: [2021.2] Microsoft DP-200 Exam Prep Actual Dumps Questions For Free Share »
Real and effective Microsoft Certifications DP-200 exam dumps and DP-200 pdf online download
Where do I find a DP-200 PDF or any dump to download? Here you can easily get the latest Microsoft Certifications DP-200 exam dumps and DP-200 pdf! We’ve compiled the latest Microsoft DP-200 exam questions and answers to help you save most of your time. Microsoft DP-200 exam “Implementing an Azure Data Solution” https://www.pass4itsure.com/dp-200.html (Q&As:86). All exam dump! Guaranteed to pass for the first time!
Microsoft Certifications DP-200 Exam pdf
[PDF] Free Microsoft DP-200 pdf dumps download from Google Drive: https://drive.google.com/open?id=1lJNE54_9AAyU9kzPI_8NR-PPFqNYM7ys
Related Microsoft Certifications Exam pdf
[PDF] Free Microsoft DP-201 pdf dumps download from Google Drive: https://drive.google.com/open?id=1voG3cYhKFklJuG3ZSghQ98UaUGLlj3MN
[PDF] Free Microsoft MD-100 pdf dumps download from Google Drive: https://drive.google.com/open?id=1s1Iy9Fx7esWTBKip_3ZweRQP2xWQIPoy
Microsoft exam certification information
Exam DP-200: Implementing an Azure Data Solution – Microsoft: https://www.microsoft.com/en-us/learning/exam-dp-200.aspx
Candidates for this exam are Microsoft Azure data engineers who collaborate with business stakeholders to identify and meet the
data requirements to implement data solutions that use Azure data services.
Azure data engineers are responsible for data-related tasks that include provisioning data storage services, ingesting streaming and batch data, transforming data, implementing security requirements, implementing data retention policies, identifying performance bottlenecks, and accessing external data sources.
Skills measured
- Implement data storage solutions (40-45%)
- Manage and develop data processing (25-30%)
- Monitor and optimize data solutions (30-35%)
Microsoft Certified: Azure Data Engineer Associate:https://www.microsoft.com/en-us/learning/azure-data-engineer.aspx
Azure Data Engineers design and implement the management, monitoring, security, and privacy of data using the full stack of Azure data services to satisfy business needs. Required exams: Exam DP-201
Microsoft Certifications DP-200 Online Exam Practice Questions
QUESTION 1
You develop data engineering solutions for a company.
A project requires the deployment of data to Azure Data Lake Storage.
You need to implement role-based access control (RBAC) so that project members can manage the Azure Data Lake
Storage resources.
Which three actions should you perform? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
A. Assign Azure AD security groups to Azure Data Lake Storage.
B. Configure end-user authentication for the Azure Data Lake Storage account.
C. Configure service-to-service authentication for the Azure Data Lake Storage account.
D. Create security groups in Azure Active Directory (Azure AD) and add project members.
E. Configure access control lists (ACL) for the Azure Data Lake Storage account.
Correct Answer: ADE
QUESTION 2
You develop data engineering solutions for a company.
You need to ingest and visualize real-time Twitter data by using Microsoft Azure.
Which three technologies should you use? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
A. Event Grid topic
B. Azure Stream Analytics Job that queries Twitter data from an Event Hub
C. Azure Stream Analytics Job that queries Twitter data from an Event Grid
D. Logic App that sends Twitter posts which have target keywords to Azure
E. Event Grid subscription
F. Event Hub instance
Correct Answer: BDF
You can use Azure Logic apps to send tweets to an event hub and then use a Stream Analytics job to read from event
hub and send them to PowerBI.
References:
https://community.powerbi.com/t5/Integrations-with-Files-and/Twitter-streaming-analytics-step-by-step/td-p/9594
QUESTION 3
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains
a unique solution that might meet the stated goals. Some questions sets might have more than one correct solution,
while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not
appear in the review screen.
You need setup monitoring for tiers 6 through 8.
What should you configure?
A. extended events for average storage percentage that emails data engineers
B. an alert rule to monitor CPU percentage in databases that emails data engineers
C. an alert rule to monitor CPU percentage in elastic pools that emails data engineers
D. an alert rule to monitor storage percentage in databases that emails data engineers
E. an alert rule to monitor storage percentage in elastic pools that emails data engineers
Correct Answer: E
Scenario:
Tiers 6 through 8 must have unexpected resource storage usage immediately reported to data engineers.
Tier 3 and Tier 6 through Tier 8 applications must use database density on the same server and Elastic pools in a cost-
effective manner.