
Where do I find a DP-200 PDF or any dump to download? Here you can easily get the latest Microsoft Certifications DP-200 exam dumps and DP-200 pdf! We’ve compiled the latest Microsoft DP-200 exam questions and answers to help you save most of your time. Microsoft DP-200 exam “Implementing an Azure Data Solution” https://www.pass4itsure.com/dp-200.html (Q&As:86). All exam dump! Guaranteed to pass for the first time!
Microsoft Certifications DP-200 Exam pdf
[PDF] Free Microsoft DP-200 pdf dumps download from Google Drive: https://drive.google.com/open?id=1lJNE54_9AAyU9kzPI_8NR-PPFqNYM7ys
Related Microsoft Certifications Exam pdf
[PDF] Free Microsoft DP-201 pdf dumps download from Google Drive: https://drive.google.com/open?id=1voG3cYhKFklJuG3ZSghQ98UaUGLlj3MN
[PDF] Free Microsoft MD-100 pdf dumps download from Google Drive: https://drive.google.com/open?id=1s1Iy9Fx7esWTBKip_3ZweRQP2xWQIPoy
Microsoft exam certification information
Exam DP-200: Implementing an Azure Data Solution – Microsoft: https://www.microsoft.com/en-us/learning/exam-dp-200.aspx
Candidates for this exam are Microsoft Azure data engineers who collaborate with business stakeholders to identify and meet the
data requirements to implement data solutions that use Azure data services.
Azure data engineers are responsible for data-related tasks that include provisioning data storage services, ingesting streaming and batch data, transforming data, implementing security requirements, implementing data retention policies, identifying performance bottlenecks, and accessing external data sources.
Skills measured
- Implement data storage solutions (40-45%)
- Manage and develop data processing (25-30%)
- Monitor and optimize data solutions (30-35%)
Microsoft Certified: Azure Data Engineer Associate:https://www.microsoft.com/en-us/learning/azure-data-engineer.aspx
Azure Data Engineers design and implement the management, monitoring, security, and privacy of data using the full stack of Azure data services to satisfy business needs. Required exams: Exam DP-201
Microsoft Certifications DP-200 Online Exam Practice Questions
QUESTION 1
You develop data engineering solutions for a company.
A project requires the deployment of data to Azure Data Lake Storage.
You need to implement role-based access control (RBAC) so that project members can manage the Azure Data Lake
Storage resources.
Which three actions should you perform? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
A. Assign Azure AD security groups to Azure Data Lake Storage.
B. Configure end-user authentication for the Azure Data Lake Storage account.
C. Configure service-to-service authentication for the Azure Data Lake Storage account.
D. Create security groups in Azure Active Directory (Azure AD) and add project members.
E. Configure access control lists (ACL) for the Azure Data Lake Storage account.
Correct Answer: ADE
QUESTION 2
You develop data engineering solutions for a company.
You need to ingest and visualize real-time Twitter data by using Microsoft Azure.
Which three technologies should you use? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
A. Event Grid topic
B. Azure Stream Analytics Job that queries Twitter data from an Event Hub
C. Azure Stream Analytics Job that queries Twitter data from an Event Grid
D. Logic App that sends Twitter posts which have target keywords to Azure
E. Event Grid subscription
F. Event Hub instance
Correct Answer: BDF
You can use Azure Logic apps to send tweets to an event hub and then use a Stream Analytics job to read from event
hub and send them to PowerBI.
References:
https://community.powerbi.com/t5/Integrations-with-Files-and/Twitter-streaming-analytics-step-by-step/td-p/9594
QUESTION 3
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains
a unique solution that might meet the stated goals. Some questions sets might have more than one correct solution,
while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not
appear in the review screen.
You need setup monitoring for tiers 6 through 8.
What should you configure?
A. extended events for average storage percentage that emails data engineers
B. an alert rule to monitor CPU percentage in databases that emails data engineers
C. an alert rule to monitor CPU percentage in elastic pools that emails data engineers
D. an alert rule to monitor storage percentage in databases that emails data engineers
E. an alert rule to monitor storage percentage in elastic pools that emails data engineers
Correct Answer: E
Scenario:
Tiers 6 through 8 must have unexpected resource storage usage immediately reported to data engineers.
Tier 3 and Tier 6 through Tier 8 applications must use database density on the same server and Elastic pools in a cost-
effective manner.
QUESTION 4
You need set up the Azure Data Factory JSON definition for Tier 10 data.
What should you use? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:
Correct Answer:

Box 1: Connection String
To use storage account key authentication, you use the ConnectionString property, which xpecify the information
needed to connect to Blobl Storage.
Mark this field as a SecureString to store it securely in Data Factory. You can also put account key in Azure Key Vault
and pull the accountKey configuration out of the connection string.
Box 2: Azure Blob
Tier 10 reporting data must be stored in Azure Blobs 
References: https://docs.microsoft.com/en-us/azure/data-factory/connector-azure-blob-storage
QUESTION 5
You need to process and query ingested Tier 9 data.
Which two options should you use? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
A. Azure Notification Hub
B. Transact-SQL statements
C. Azure Cache for Redis
D. Apache Kafka statements
E. Azure Event Grid
F. Azure Stream Analytics
Correct Answer: EF
Explanation:
Event Hubs provides a Kafka endpoint that can be used by your existing Kafka based applications as an alternative to
running your own Kafka cluster.
You can stream data into Kafka-enabled Event Hubs and process it with Azure Stream Analytics, in the following steps:
Create a Kafka enabled Event Hubs namespace.
Create a Kafka client that sends messages to the event hub.
Create a Stream Analytics job that copies data from the event hub into an Azure blob storage.
Scenario:
Tier 9 reporting must be moved to Event Hubs, queried, and persisted in the same Azure region as the company’s main
office
References: https://docs.microsoft.com/en-us/azure/event-hubs/event-hubs-kafka-stream-analytics
QUESTION 6
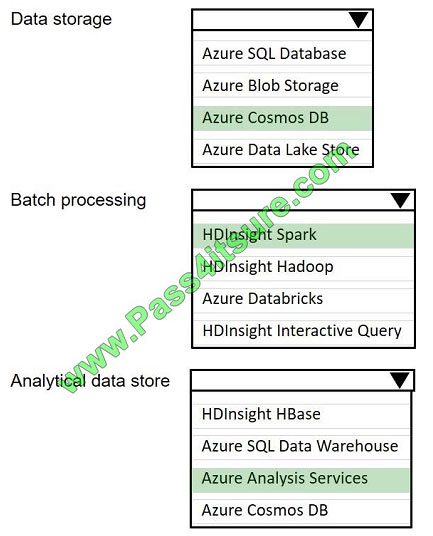
You are developing a solution using a Lambda architecture on Microsoft Azure.
The data at test layer must meet the following requirements:
Data storage:
-Serve as a repository (or high volumes of large files in various formats.
-Implement optimized storage for big data analytics workloads.
-Ensure that data can be organized using a hierarchical structure. Batch processing:
-Use a managed solution for in-memory computation processing.
-Natively support Scala, Python, and R programming languages.
-Provide the ability to resize and terminate the cluster automatically. Analytical data store:
-Support parallel processing.
-Use columnar storage.
-Support SQL-based languages. You need to identify the correct technologies to build the Lambda architecture. Which
technologies should you use? To answer, select the appropriate options in the answer area NOTE: Each correct
selection is worth one point.
Hot Area:

Correct Answer:
QUESTION 7
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains
a unique solution. Determine whether the solution meets the stated goals.
You develop a data ingestion process that will import data to a Microsoft Azure SQL Data Warehouse. The data to be
ingested resides in parquet files stored in an Azure Data lake Gen 2 storage account.
You need to load the data from the Azure Data Lake Gen 2 storage account into the Azure SQL Data Warehouse.
Solution;
1.
Create an external data source pointing to the Azure Data Lake Gen 2 storage account.
2.
Create an external tile format and external table using the external data source.
3.
Load the data using the CREATE TABLE AS SELECT statement. Does the solution meet the goal?
A. Yes
B. No
Correct Answer: A
QUESTION 8
You manage a process that performs analysis of daily web traffic logs on an HDInsight cluster. Each of 250 web servers
generates approximately gigabytes (GB) of log data each day. All log data is stored in a single folder in Microsoft Azure
Data Lake Storage Gen 2.
You need to improve the performance of the process.
Which two changes should you make? Each correct answer presents a complete solution.
NOTE: Each correct selection is worth one point.
A. Combine the daily log files for all servers into one file
B. Increase the value of the mapreduce.map.memory parameter
C. Move the log files into folders so that each day\\’s logs are in their own folder
D. Increase the number of worker nodes
E. Increase the value of the hive.tez.container.size parameter
Correct Answer: AC
A: Typically, analytics engines such as HDInsight and Azure Data Lake Analytics have a per-file overhead. If you store
your data as many small files, this can negatively affect performance. In general, organize your data into larger sized
files for better performance (256MB to 100GB in size). Some engines and applications might have trouble efficiently
processing files that are greater than 100GB in size.
C: For Hive workloads, partition pruning of time-series data can help some queries read only a subset of the data which
improves performance.
Those pipelines that ingest time-series data, often place their files with a very structured naming for files and folders.
Below is a very common example we see for data that is structured by date:
\DataSet\YYYY\MM\DD\datafile_YYYY_MM_DD.tsv
Notice that the datetime information appears both as folders and in the filename.
References:
https://docs.microsoft.com/en-us/azure/storage/blobs/data-lake-storage-performance-tuning-guidance
QUESTION 9
A company builds an application to allow developers to share and compare code. The conversations, code snippets,
and links shared by people in the application are stored in a Microsoft Azure SQL Database instance. The application
allows for searches of historical conversations and code snippets.
When users share code snippets, the code snippet is compared against previously share code snippets by using a
combination of Transact-SQL functions including SUBSTRING, FIRST_VALUE, and SQRT. If a match is found, a link to
the match is added to the conversation.
Customers report the following issues: Delays occur during live conversations A delay occurs before matching links
appear after code snippets are added to conversations
You need to resolve the performance issues.
Which technologies should you use? To answer, drag the appropriate technologies to the correct issues. Each
technology may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll
to view content.
NOTE: Each correct selection is worth one point.
Select and Place:
Correct Answer:
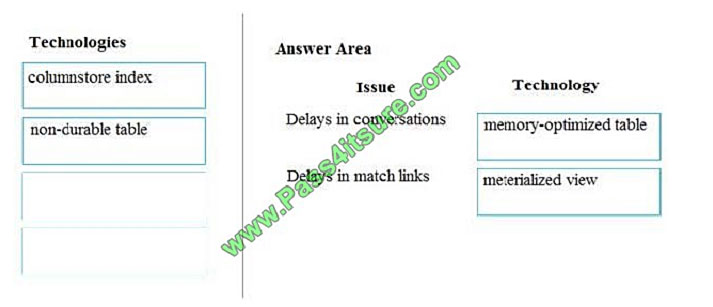
Box 1: memory-optimized table
In-Memory OLTP can provide great performance benefits for transaction processing, data ingestion, and transient data
scenarios.
Box 2: materialized view
To support efficient querying, a common solution is to generate, in advance, a view that materializes the data in a format
suited to the required results set. The Materialized View pattern describes generating prepopulated views of data in
environments where the source data isn\\’t in a suitable format for querying, where generating a suitable query is
difficult, or where query performance is poor due to the nature of the data or the data store.
These materialized views, which only contain data required by a query, allow applications to quickly obtain the
information they need. In addition to joining tables or combining data entities, materialized views can include the current
values of
calculated columns or data items, the results of combining values or executing transformations on the data items, and
values specified as part of the query. A materialized view can even be optimized for just a single query.
References:
https://docs.microsoft.com/en-us/azure/architecture/patterns/materialized-view
QUESTION 10
Note: This question is part of series of questions that present the same scenario. Each question in the series contain a
unique solution. Determine whether the solution meets the stated goals.
You develop a data ingestion process that will import data to a Microsoft Azure SQL Data Warehouse. The data to be
ingested resides in parquet files stored in an Azure Data Lake Gen 2 storage account.
You need to load the data from the Azure Data Lake Gen 2 storage account into the Azure SQL Data Warehouse.
Solution:
1.
Use Azure Data Factory to convert the parquet files to CSV files
2.
Create an external data source pointing to the Azure storage account
3.
Create an external file format and external table using the external data source
4.
Load the data using the INSERT…SELECT statement Does the solution meet the goal?
A. Yes
B. No
Correct Answer: B
There is no need to convert the parquet files to CSV files.
You load the data using the CREATE TABLE AS SELECT statement.
References:
https://docs.microsoft.com/en-us/azure/sql-data-warehouse/sql-data-warehouse-load-from-azure-data-lake-store
QUESTION 11
You manage security for a database that supports a line of business application.
Private and personal data stored in the database must be protected and encrypted.
You need to configure the database to use Transparent Data Encryption (TDE).
Which five actions should you perform in sequence? To answer, select the appropriate actions from the list of actions to
the answer area and arrange them in the correct order.
Select and Place: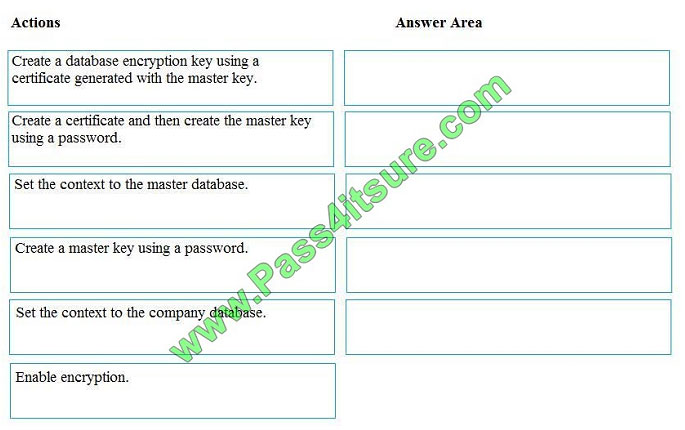
Correct Answer:

Step 1: Create a master key
Step 2: Create or obtain a certificate protected by the master key
Step 3: Set the context to the company database
Step 4: Create a database encryption key and protect it by the certificate
Step 5: Set the database to use encryption
Example code: USE master; GO CREATE MASTER KEY ENCRYPTION BY PASSWORD = \\’\\’; go CREATE
CERTIFICATE MyServerCert WITH SUBJECT = \\’My DEK Certificate\\’; go USE AdventureWorks2012; GO CREATE
DATABASE ENCRYPTION KEY WITH ALGORITHM = AES_128 ENCRYPTION BY SERVER CERTIFICATE
MyServerCert; GO ALTER DATABASE AdventureWorks2012 SET ENCRYPTION ON; GO
References: https://docs.microsoft.com/en-us/sql/relational-databases/security/encryption/transparent-data-encryption
QUESTION 12
You develop data engineering solutions for a company.
A project requires analysis of real-time Twitter feeds. Posts that contain specific keywords must be stored and
processed on Microsoft Azure and then displayed by using Microsoft Power BI. You need to implement the solution.
Which five actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to
the answer area and arrange them in the correct order.
Select and Place:
Correct Answer:

Step 1: Create an HDInisght cluster with the Spark cluster type
Step 2: Create a Jyputer Notebook
Step 3: Create a table
The Jupyter Notebook that you created in the previous step includes code to create an hvac table.
Step 4: Run a job that uses the Spark Streaming API to ingest data from Twitter
Step 5: Load the hvac table into Power BI Desktop
You use Power BI to create visualizations, reports, and dashboards from the Spark cluster data.
References:
https://acadgild.com/blog/streaming-twitter-data-using-spark
https://docs.microsoft.com/en-us/azure/hdinsight/spark/apache-spark-use-with-data-lake-store
QUESTION 13
You are creating a managed data warehouse solution on Microsoft Azure.
You must use PolyBase to retrieve data from Azure Blob storage that resides in parquet format and toad the data into a
large table called FactSalesOrderDetails.
You need to configure Azure SQL Data Warehouse to receive the data.
Which four actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to
the answer area and arrange them in the correct order.
Select and Place: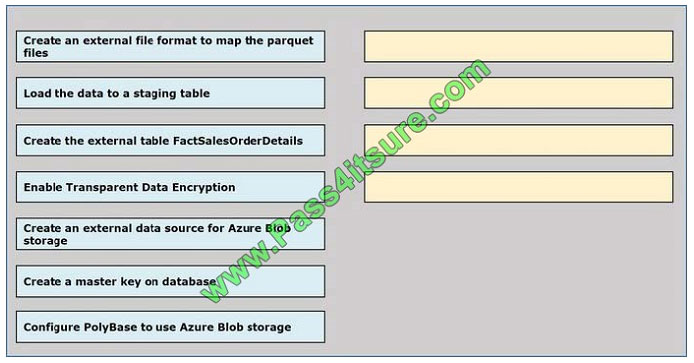
Correct Answer:

Share Pass4itsure discount codes for free

The benefits of Pass4itsure!
Pass4itsure offers the latest exam practice questions and answers free of charge! Update all exam questions throughout the year,
with a number of professional exam experts! To make sure it works! Maximum pass rate, best value for money! Helps you pass the exam easily on your first attempt.
This maybe you’re interested
Summarize:
Get the full Microsoft Certifications DP-200 exam dump here: https://www.pass4itsure.com/dp-200.html (Q&As:86). Follow my blog and we regularly update the latest effective exam dumps to help you improve your skills!
Discover more from Exampass: Collection of Cisco (CCNA, CCNP, Meraki Solutions Specialist, CCDP...) exam questions and answers from Pass4itsure
Subscribe to get the latest posts sent to your email.