
Pass4itsure share these resources with you. Both VCE and PDF dumps contain the latest Microsoft DP-100 exam questions, which will ensure your DP-100 exam 100% passed! You can get DP-100 VCE dumps and DP-100 PDF dumps from Pass4itsure. Please get the latest Pass4itsure DP-100 dumps here: https://www.pass4itsure.com/dp-100.html(220 QA Dumps).
Download The Real Microsoft DP-100 PDF Here, Free
[free pdf] Microsoft DP-100 PDF [Drive] https://drive.google.com/file/d/1KQjW9IWlT8W8Qd9bqjLKYyzpP-3Zk4lU/view?usp=sharing
Microsoft DP-100 Practice Test Questions Answers
QUESTION 1
DRAG DROP
An organization uses Azure Machine Learning service and wants to expand its use of machine learning.
You have the following compute environments. The organization does not want to create another compute
environment.
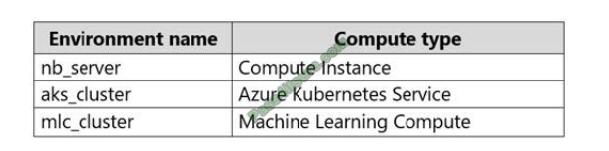
You need to determine which compute environment to use for the following scenarios.
Which compute types should you use? To answer, drag the appropriate compute environments to the correct scenarios.
Each computing environment may be used once, more than once, or not at all. You may need to drag the split bar
between
panes or scroll to view content.
NOTE: Each correct selection is worth one point.
Select and Place:

Box 1: nb_server Box 2: mlc_cluster With Azure Machine Learning, you can train your model on a variety of resources
or environments, collectively referred to as compute targets. A computing target can be a local machine or a cloud
resource, such as an Azure Machine Learning Compute, Azure HDInsight, or a remote virtual machine.
Reference:
https://docs.microsoft.com/en-us/azure/machine-learning/concept-compute-target
https://docs.microsoft.com/en-us/azure/machine-learning/how-to-set-up-training-targets
QUESTION 2
HOTSPOT
You are tuning a hyperparameter for an algorithm. The following table shows a data set with different hyperparameter,
training error, and validation errors.
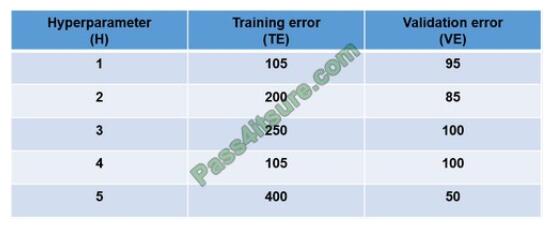
Use the drop-down menus to select the answer choice that answers each question based on the information presented
in the graphic.
Hot Area:

Correct Answer:

Box 1: 4
Choose the one which has lower training and validation error and also the closest match.
Minimize variance (the difference between validation error and train error).
Box 2: 5
Minimize variance (the difference between validation error and train error).
Reference:
https://medium.com/comet-ml/organizing-machine-learning-projects-project-management-guidelines-2d2b85651bbd
QUESTION 3
You need to visually identify whether outliers exist in the Age column and quantify the outliers before the outliers are
removed. Which three Azure Machine Learning Studio modules should you use? Each correct answer presents part of
the solution. NOTE: Each correct selection is worth one point.
A. Create Scatterplot
B. Summarize Data
C. Clip Values
D. Replace Discrete Values
E. Build Counting Transform
Correct Answer: ABC
B: To have a global view, the summarize data module can be used. Add the module and connect it to the data set that
needs to be visualized.
A: One way to quickly identify Outliers visually is to create scatter plots.
C: The easiest way to treat the outliers in Azure ML is to use the Clip Values module. It can identify and optionally
replace data values that are above or below a specified threshold.
You can use the Clip Values module in Azure Machine Learning Studio, to identify and optionally replace data values
that are above or below a specified threshold. This is useful when you want to remove outliers or replace them with a
mean, a constant, or other substitute value.
References: https://blogs.msdn.microsoft.com/azuredev/2017/05/27/data-cleansing-tools-in-azure-machine-learning/
https://docs.microsoft.com/en-us/azure/machine-learning/studio-module-reference/clip-values Question Set 3
QUESTION 4
You have a dataset created for multiclass classification tasks that contains a normalized numerical feature set with
10,000 data points and 150 features.
You use 75 percent of the data points for training and 25 percent for testing. You are using the scikit-learn machine
learning library in Python. You use X to denote the feature set and Y to denote class labels.
You create the following Python data frames:
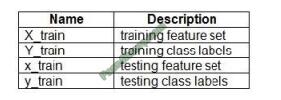
You need to apply the Principal Component Analysis (PCA) method to reduce the dimensionality of the feature set to 10
features in both training and testing sets.
How should you complete the code segment? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:

Box 1: PCA(n_components = 10)
Need to reduce the dimensionality of the feature set to 10 features in both training and testing sets.
Example:
from sklearn.decomposition import PCA
pca = PCA(n_components=2) ;2 dimensions
principalComponents = pca.fit_transform(x)
Box 2: pca
fit_transform(X[, y])fits the model with X and apply the dimensionality reduction on X.
Box 3: transform(x_test)
transform(X) applies dimensionality reduction to X.
References:
https://scikit-learn.org/stable/modules/generated/sklearn.decomposition.PCA.html
QUESTION 5
HOTSPOT
You deploy a model in Azure Container Instance.
You must use the Azure Machine Learning SDK to call the model API.
You need to invoke the deployed model using native SDK classes and methods.
How should you complete the command? To answer, select the appropriate options in the answer areas.
NOTE: Each correct selection is worth one point.
Hot Area:
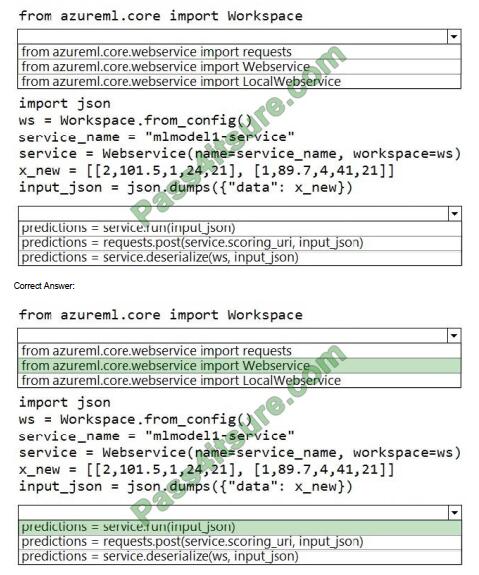
Box 1: from azureml.core.webservice import Webservice
The following code shows how to use the SDK to update the model, environment, and entry script for a web service to Azure Container Instances:
from azureml.core import Environment
from azureml.core.webservice import Webservice
from azureml.core.model import Model, InferenceConfig
Box 2: predictions = service.run(input_json)
Example: The following code demonstrates sending data to the service:
import json
test_sample = json.dumps({\\’data\\’: [ [1, 2, 3, 4, 5, 6, 7, 8, 9, 10], [10, 9, 8, 7, 6, 5, 4, 3, 2, 1]
]})
test_sample = bytes(test_sample, encoding=\\’utf8\\’)
prediction = service.run(input_data=test_sample) print(prediction)
Reference: https://docs.microsoft.com/bs-latn-ba/azure/machine-learning/how-to-deploy-azure-container-instance
https://docs.microsoft.com/en-us/azure/machine-learning/how-to-troubleshoot-deployment
QUESTION 6
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains
a unique solution that might meet the stated goals. Some question sets might have more than one correct solution,
while
others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not
appear in the review screen.
You create a model to forecast weather conditions based on historical data.
You need to create a pipeline that runs a processing script to load data from a datastore and pass the processed data to
a machine learning model training script.
Solution: Run the following code:

Does the solution meet the goal?
A. Yes
B. No
Correct Answer: A
The two steps are present: process_step and train_step
Data_input correctly references the data in the data store.
Note:
Data used in pipeline can be produced by one step and consumed in another step by providing a PipelineData object as
an output of one step and an input of one or more subsequent steps.
PipelineData objects are also used when constructing Pipelines to describe step dependencies. To specify that a step
requires the output of another step as input, use a PipelineData object in the constructor of both steps.
For example, the pipeline train step depends on the process_step_output output of the pipeline process step:
from azureml.pipeline.core import Pipeline, PipelineData from azureml.pipeline.steps import PythonScriptStep
datastore = ws.get_default_datastore()
process_step_output = PipelineData(“processed_data”, datastore=datastore) process_step =
PythonScriptStep(script_name=”process.py”, arguments=[“–data_for_train”, process_step_output],
outputs=[process_step_output],
compute_target=aml_compute,
source_directory=process_directory)
train_step = PythonScriptStep(script_name=”train.py”,
arguments=[“–data_for_train”, process_step_output],
inputs=[process_step_output],
compute_target=aml_compute,
source_directory=train_directory)
pipeline = Pipeline(workspace=ws, steps=[process_step, train_step])
Reference:
https://docs.microsoft.com/en-us/python/api/azureml-pipeline-core/azureml.pipeline.core.pipelinedata?view=azure-mlpy
QUESTION 7
HOTSPOT
You are using Azure Machine Learning to train machine learning models. You need to compute the target on which to
remotely run the training script.
You run the following Python code:

For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.
Hot Area:

Correct Answer:

Box 1: Yes
The compute is created within your workspace region as a resource that can be shared with other users.
Box 2: Yes
It is displayed as a compute cluster.
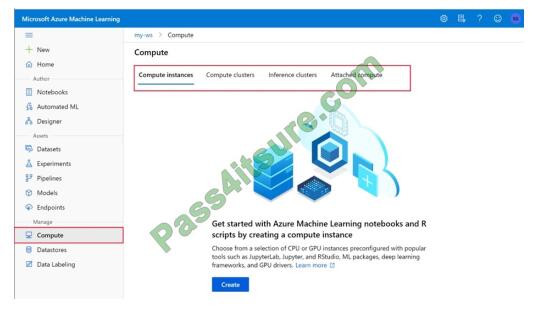
View compute targets
1.
To see all compute targets for your workspace, use the following steps:
2.
Navigate to Azure Machine Learning studio.
3.
Under Manage, select Compute.
4.
Select tabs at the top to show each type of computing target.
Box 3: Yes
min_nodes is not specified, so it defaults to 0.
Reference:
https://docs.microsoft.com/en-us/python/api/azuremlcore/azureml.core.compute.amlcompute.amlcomputeprovisioningconfiguration
https://docs.microsoft.com/en-us/azure/machine-learning/how-to-create-attach-compute-studio
QUESTION 8
HOTSPOT
You are performing a classification task in Azure Machine Learning Studio.
You must prepare balanced testing and training samples based on a provided data set.
You need to split the data with a 0.75:0.25 ratio.
Which value should you use for each parameter? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:

Correct Answer:

Box 1: Split rows
Use the Split Rows option if you just want to divide the data into two parts. You can specify the percentage of data to put
in each split, but by default, the data is divided 50-50.
You can also randomize the selection of rows in each group, and use stratified sampling. In stratified sampling, you
must select a single column of data for which you want values to be apportioned equally among the two result datasets.
Box 2: 0.75
If you specify a number as a percentage, or if you use a string that contains the “%” character, the value is interpreted
as a percentage. All percentage values must be within the range (0, 100), not including the values 0 and 100.
Box 3: Yes
To ensure splits are balanced.
Box 4: No
If you use the option for a stratified split, the output datasets can be further divided by subgroups, by selecting a strata
column.
Reference:
https://docs.microsoft.com/en-us/azure/machine-learning/studio-module-reference/split-data
QUESTION 9
You use the Azure Machine Learning Studio to build a machine learning experiment.
You need to divide data into two distinct datasets.
Which module should you use?
A. Assign Data to Clusters
B. Load Trained Model
C. Partition and Sample
D. Tune Model-Hyperparameters
Correct Answer: C
Partition and Sample with the Stratified split option outputs multiple datasets, partitioned using the rules you specified.
References: https://docs.microsoft.com/en-us/azure/machine-learning/studio-module-reference/partition-and-sample
QUESTION 10
You are creating a binary classification by using a two-class logistic regression model.
You need to evaluate the model results for imbalance.
Which evaluation metric should you use?
A. Relative Absolute Error
B. AUC Curve
C. Mean Absolute Error
D. Relative Squared Error
E. Accuracy
F. Root Mean Square Error
Correct Answer: B
One can inspect the true positive rate vs. the false positive rate in the Receiver Operating Characteristic (ROC) curve
and the corresponding Area Under the Curve (AUC) value. The closer this curve is to the upper left corner, the better
the
classifier\\’s performance is (that is maximizing the true positive rate while minimizing the false positive rate). Curves
that are close to the diagonal of the plot, result from classifiers that tend to make predictions that are close to random
guessing.
Reference:
https://docs.microsoft.com/en-us/azure/machine-learning/studio/evaluate-model-performance#evaluating-a-binaryclassification-model
QUESTION 11
You are solving a classification task.
You must evaluate your model on a limited data sample by using k-fold cross-validation. You start by configuring a k
parameter as the number of splits.
You need to configure the k parameter for the cross-validation.
Which value should you use?
A. k=0.5
B. k=0.01
C. k=5
D. k=1
Correct Answer: C
Leave One Out (LOO) cross-validation
Setting K = n (the number of observations) yields n-fold and is called leave-one-out cross-validation (LOO), a special
case of the K-fold approach.
LOO CV is sometimes useful but typically doesn\\’t shake up the data enough. The estimates from each fold are highly
correlated and hence their average can have high variance. This is why the usual choice is K=5 or 10. It provides a
good
compromise for the bias-variance tradeoff.
QUESTION 12
You are creating a machine learning model. You have a dataset that contains null rows.
You need to use the Clean Missing Data module in Azure Machine Learning Studio to identify and resolve the null and
missing data in the dataset.
Which parameter should you use?
A. Replace with mean
B. Remove entire column
C. Remove entire row
D. Hot Deck
E. Custom substitution value
F. Replace with mode
Correct Answer: C
Remove entire row: Completely removes any row in the dataset that has one or more missing values. This is useful if
the missing value can be considered randomly missing.
References: https://docs.microsoft.com/en-us/azure/machine-learning/studio-module-reference/clean-missing-data
QUESTION 13
You are implementing a machine learning model to predict stock prices.
The model uses a PostgreSQL database and requires GPU processing.
You need to create a virtual machine that is pre-configured with the required tools.
What should you do?
A. Create a Data Science Virtual Machine (DSVM) Windows edition.
B. Create a Geo Al Data Science Virtual Machine (Geo-DSVM) Windows edition.
C. Create a Deep Learning Virtual Machine (DLVM) Linux edition.
D. Create a Deep Learning Virtual Machine (DLVM) Windows edition.
Correct Answer: A
In the DSVM, your training models can use deep learning algorithms on hardware that\\’s based on graphics processing
units (GPUs).
PostgreSQL is available for the following operating systems: Linux (all recent distributions), 64-bit installers available for
macOS (OS X) version 10.6 and newer? Windows (with installers available for 64-bit version; tested on latest versions
and back to Windows 2012 R2.
Incorrect Answers:
B: The Azure Geo AI Data Science VM (Geo-DSVM) delivers geospatial analytics capabilities from Microsoft\\’s Data Science VM. Specifically, this VM extends the AI and data science toolkits in the Data Science VM by adding ESRI\\’s
market-leading ArcGIS Pro Geographic Information System.
C, D: DLVM is a template on top of the DSVM image. In terms of the packages, GPU drivers, etc are all there in the DSVM
image. Mostly it is for convenience during creation where we only allow DLVM to be created on GPU VM instances on
Azure.
Reference: https://docs.microsoft.com/en-us/azure/machine-learning/data-science-virtual-machine/overview
Pass4itsure Discount Code 2020

P.S
Exampass shares all the resources: Latest Microsoft DP-100 practice questions, latest DP-100 pdf dumps, DP-100 exam video learning. Microsoft DP-100 dumps https://www.pass4itsure.com/dp-100.html has come to help you prepare for the implementation of the Microsoft DP-100 exam and its comprehensive and thorough DP-100 exam practice materials, which will help you successfully pass the examination.
Discover more from Exampass: Collection of Cisco (CCNA, CCNP, Meraki Solutions Specialist, CCDP...) exam questions and answers from Pass4itsure
Subscribe to get the latest posts sent to your email.