
Valid Microsoft DP-100 questions shared by Pass4itsure for helping to pass the Microsoft DP-100 exam! Get the newest Pass4itsure Microsoft DP-100 exam dumps with VCE and PDF here: https://www.pass4itsure.com/dp-100.html (115 Q&As Dumps).
[Free PDF] Microsoft DP-100 pdf Q&As https://drive.google.com/file/d/1bgabrbEkC7jgRfSH7PzsyvjlYfErKLHm/view?usp=sharing
Suitable for DP-100 complete Microsoft learning pathway
The content is rich and diverse, and learning will not become boring. You can learn in multiple ways through the Microsoft DP-100 exam.
- Download
- Answer practice questions, the actual Microsoft DP-100 test
Microsoft DP-100 Designing and Implementing a Data Science Solution on Azure
Free Microsoft DP-100 dumps download
[PDF] Free Microsoft DP-100 dumps pdf download https://drive.google.com/file/d/1bgabrbEkC7jgRfSH7PzsyvjlYfErKLHm/view?usp=sharing
Pass4itsure offers the latest Microsoft DP-100 practice test free of charge 1-13
QUESTION 1
You are building an intelligent solution using machine learning models.
The environment must support the following requirements:
Data scientists must build notebooks in a cloud environment
Data scientists must use automatic feature engineering and model building in machine learning pipelines. Notebooks
must be deployed to retrain using Spark instances with dynamic worker allocation. Notebooks must be exportable to be
version controlled locally.
You need to create the environment.
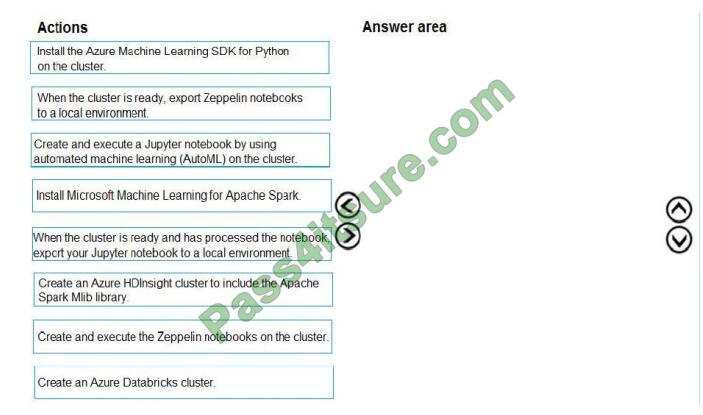
Which four actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to
the answer area and arrange them in the correct order.
Select and Place:
Correct Answer:
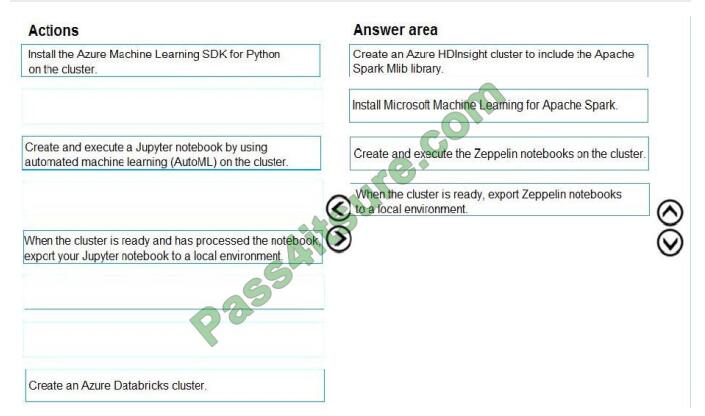
Step 1: Create an Azure HDInsight cluster to include the Apache Spark Mlib library
Step 2: Install Microsot Machine Learning for Apache Spark
You install AzureML on your Azure HDInsight cluster.
Microsoft Machine Learning for Apache Spark (MMLSpark) provides a number of deep learning and data science tools
for Apache Spark, including seamless integration of Spark Machine Learning pipelines with Microsoft Cognitive Toolkit
(CNTK) and OpenCV, enabling you to quickly create powerful, highly-scalable predictive and analytical models for large
image and text datasets.
Step 3: Create and execute the Zeppelin notebooks on the cluster
Step 4: When the cluster is ready, export Zeppelin notebooks to a local environment.
Notebooks must be exportable to be version controlled locally.
References:
https://docs.microsoft.com/en-us/azure/hdinsight/spark/apache-spark-zeppelin-notebook
https://azuremlbuild.blob.core.windows.net/pysparkapi/intro.html
QUESTION 2
You need to resolve the local machine learning pipeline performance issue. What should you do?
A. Increase Graphic Processing Units (GPUs).
B. Increase the learning rate.
C. Increase the training iterations.
D. Increase Central Processing Units (CPUs).
Correct Answer: A
QUESTION 3
HOTSPOT
You are developing a deep learning model by using TensorFlow. You plan to run the model training workload on an
Azure Machine Learning Compute Instance.
You must use CUDA-based model training.
You need to provision the Compute Instance.
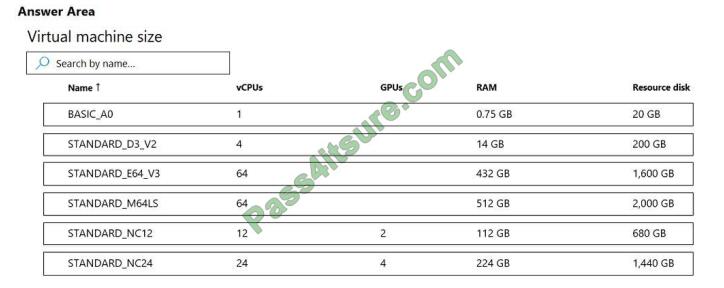
Which two virtual machines sizes can you use? To answer, select the appropriate virtual machine sizes in the answer
area.
NOTE: Each correct selection is worth one point.
Hot Area:
Correct Answer:
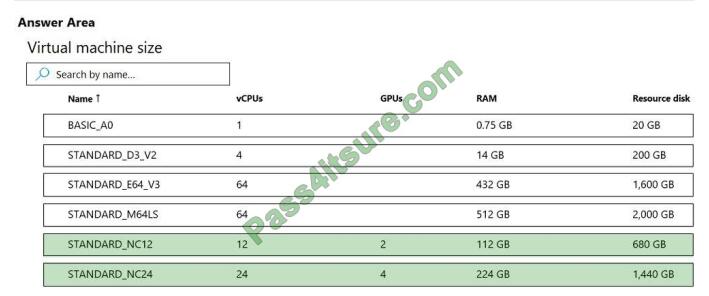
CUDA is a parallel computing platform and programming model developed by Nvidia for general computing on its own
GPUs (graphics processing units). CUDA enables developers to speed up compute-intensive applications by
harnessing the power of GPUs for the parallelizable part of the computation.
Reference: https://www.infoworld.com/article/3299703/what-is-cuda-parallel-programming-for-gpus.html
QUESTION 4
You need to replace the missing data in the AccessibilityToHighway columns.
How should you configure the Clean Missing Data module? To answer, select the appropriate options in the answer
area.
NOTE: Each correct selection is worth one point.
Hot Area:

Correct Answer:
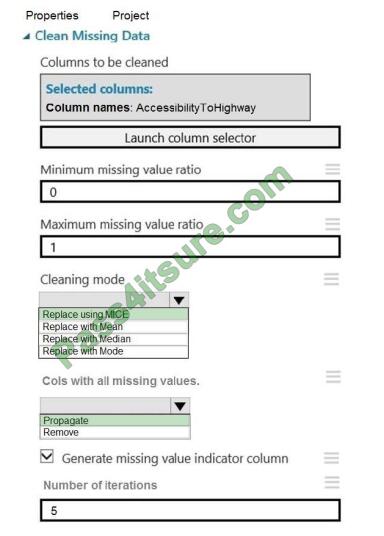
Box 1: Replace using MICE
Replace using MICE: For each missing value, this option assigns a new value, which is calculated by using a method
described in the statistical literature as “Multivariate Imputation using Chained Equations” or “Multiple Imputation by
Chained Equations”. With a multiple imputation method, each variable with missing data is modeled conditionally using
the other variables in the data before filling in the missing values.
Scenario: The AccessibilityToHighway column in both datasets contains missing values. The missing data must be
replaced with new data so that it is modeled conditionally using the other variables in the data before filling in the
missing
values.
Box 2: Propagate
Cols with all missing values indicate if columns of all missing values should be preserved in the output.
References:
https://docs.microsoft.com/en-us/azure/machine-learning/studio-module-reference/clean-missing-data
QUESTION 5
You create an Azure Machine Learning compute resource to train models. The compute resource is configured as
follows:
1. Minimum nodes: 2
2. Maximum nodes: 4
You must decrease the minimum number of nodes and increase the maximum number of nodes to the following values:
1. Minimum nodes: 0
2. Maximum nodes: 8
You need to reconfigure the compute resource.
What are three possible ways to achieve this goal? Each correct answer presents a complete solution.
NOTE: Each correct selection is worth one point.
A. Use the Azure Machine Learning studio.
B. Run the update method of the AmlCompute class in the Python SDK.
C. Use the Azure portal.
D. Use the Azure Machine Learning designer.
E. Run the refresh_state() method of the BatchCompute class in the Python SDK.
Correct Answer: ABC
A: You can manage assets and resources in the Azure Machine Learning studio.
B: The update(min_nodes=None, max_nodes=None, idle_seconds_before_scaledown=None) of the AmlCompute class
updates the ScaleSettings for this AmlCompute target.
C: To change the nodes in the cluster, use the UI for your cluster in the Azure portal.
Reference: https://docs.microsoft.com/en-us/python/api/azureml-core/azureml.core.compute.amlcompute(class)
QUESTION 6
DRAG DROP
You are producing a multiple linear regression model in Azure Machine learning Studio.
Several independent variables are highly correlated.
You need to select appropriate methods for conducting elective feature engineering on all the data;
Which three actions should you perform in sequence? To answer, move the appropriate Actions from the list of actions
to the answer area and arrange them in the correct order.
Select and Place:
Correct Answer:

QUESTION 7
DRAG DROP
You configure a Deep Learning Virtual Machine for Windows.
You need to recommend tools and frameworks to perform the following:
1.
Build deep neural network (DNN) models
2.
Perform interactive data exploration and visualization
Which tools and frameworks should you recommend? To answer, drag the appropriate tools to the correct tasks. Each
tool may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to
view
content.
NOTE: Each correct selection is worth one point.
Select and Place:

Box 1: Vowpal Wabbit
Use the Train Vowpal Wabbit Version 8 module in Azure Machine Learning Studio (classic), to create a machine
learning model by using Vowpal Wabbit.
Box 2: PowerBI Desktop
Power BI Desktop is a powerful visual data exploration and interactive reporting tool
BI is a name given to a modern approach to business decision making in which users are empowered to find, explore,
and share insights from data across the enterprise.
References:
https://docs.microsoft.com/en-us/azure/machine-learning/studio-module-reference/train-vowpal-wabbit-version-8-model
https://docs.microsoft.com/en-us/azure/architecture/data-guide/scenarios/interactive-data-exploration
QUESTION 8
You have a comma-separated values (CSV) file containing data from which you want to train a classification model.
You are using the Automated Machine Learning interface in Azure Machine Learning studio to train the classification
model. You set the task type to Classification.
You need to ensure that the Automated Machine Learning process evaluates only linear models.
What should you do?
A. Add all algorithms other than linear ones to the blocked algorithms list.
B. Set the Exit criterion option to a metric score threshold.
C. Clear the option to perform automatic featurization.
D. Clear the option to enable deep learning.
E. Set the task type to Regression.
Correct Answer: C
Automatic featurization can fit non-linear models.
Reference: https://econml.azurewebsites.net/spec/estimation/dml.html https://docs.microsoft.com/en-us/azure/machinelearning/how-to-use-automated-ml-for-ml-models
QUESTION 9
You use Azure Machine Learning Studio to build a machine learning experiment.
You need to divide data into two distinct datasets.
Which module should you use?
A. Assign Data to Clusters
B. Load Trained Model
C. Partition and Sample
D. Tune Model-Hyperparameters
Correct Answer: C
Partition and Sample with the Stratified split option outputs multiple datasets, partitioned using the rules you specified.
References: https://docs.microsoft.com/en-us/azure/machine-learning/studio-module-reference/partition-and-sample
QUESTION 10
You create a deep learning model for image recognition on Azure Machine Learning service using GPU- based training.
You must deploy the model to a context that allows for real-time GPU-based inferencing.
You need to configure compute resources for model inferencing.
Which compute type should you use?
A. Azure Container Instance
B. Azure Kubernetes Service
C. Field Programmable Gate Array
D. Machine Learning Compute
Correct Answer: B
You can use Azure Machine Learning to deploy a GPU-enabled model as a web service. Deploying a model on Azure
Kubernetes Service (AKS) is one option. The AKS cluster provides a GPU resource that is used by the model for
inference.
Inference, or model scoring, is the phase where the deployed model is used to make predictions. Using GPUs instead of
CPUs offer performance advantages on highly parallelizable computation.
Reference: https://docs.microsoft.com/en-us/azure/machine-learning/how-to-deploy-inferencing-gpus
QUESTION 11
You are using a decision tree algorithm. You have trained a model that generalizes well at a tree depth equal to 10.
You need to select the bias and variance properties of the model with varying tree depth values.
Which properties should you select for each tree depth? To answer, select the appropriate options in the answer area.
Hot Area:
Correct Answer:
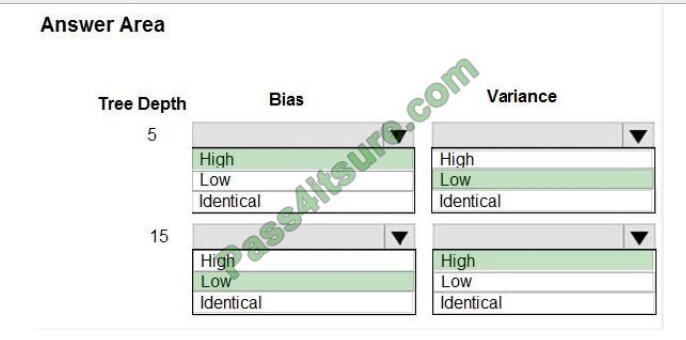
In decision trees, the depth of the tree determines the variance. A complicated decision tree (e.g. deep) has low bias
and high variance.
Note: In statistics and machine learning, the bias–variance tradeoff is the property of a set of predictive models whereby
models with a lower bias in parameter estimation have a higher variance of the parameter estimates across samples,
and vice versa. Increasing the bias will decrease the variance. Increasing the variance will decrease the bias.
References:
https://machinelearningmastery.com/gentle-introduction-to-the-bias-variance-trade-off-in-machine-learning/
QUESTION 12
DRAG DROP
You need to define an evaluation strategy for the crowd sentiment models.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions
to the answer area and arrange them in the correct order.
Select and Place:
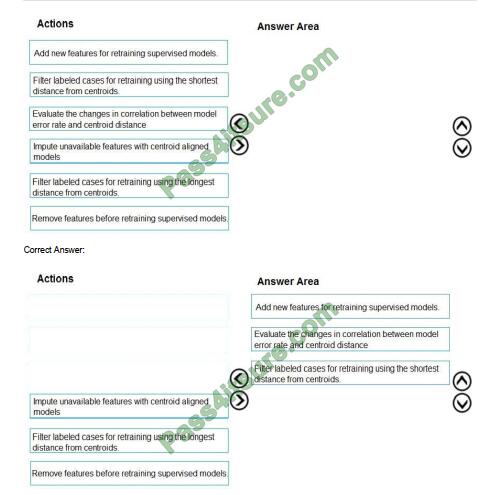
Scenario:
Experiments for local crowd sentiment models must combine local penalty detection data.
Crowd sentiment models must identify known sounds such as cheers and known catch phrases. Individual crowd
sentiment models will detect similar sounds.
Note: Evaluate the changed in correlation between model error rate and centroid distance
In machine learning, a nearest centroid classifier or nearest prototype classifier is a classification model that assigns to
observations the label of the class of training samples whose mean (centroid) is closest to the observation.
References:
https://en.wikipedia.org/wiki/Nearest_centroid_classifier
https://docs.microsoft.com/en-us/azure/machine-learning/studio-module-reference/sweep-clustering
QUESTION 13
You are creating a new Azure Machine Learning pipeline using the designer.
The pipeline must train a model using data in a comma-separated values (CSV) file that is published on a website. You
have not created a dataset for this file.
You need to ingest the data from the CSV file into the designer pipeline using the minimal administrative effort.
Which module should you add to the pipeline in Designer?
A. Convert to CSV
B. Enter Data Manually
C. Import Data
D. Dataset
Correct Answer: D
The preferred way to provide data to a pipeline is a Dataset object. The Dataset object points to data that lives in or is
accessible from a datastore or at a Web URL. The Dataset class is abstract, so you will create an instance of either a
FileDataset (referring to one or more files) or a TabularDataset that\\’s created by from one or more files with delimited
columns of data.
Example:
from azureml.core import Dataset
iris_tabular_dataset = Dataset.Tabular.from_delimited_files([(def_blob_store, \\’train-dataset/iris.csv\\’)])
Reference:
https://docs.microsoft.com/en-us/azure/machine-learning/how-to-create-your-first-pipeline
Summarize:
[Q1-Q13] Free Microsoft DP-100 pdf download https://drive.google.com/file/d/1bgabrbEkC7jgRfSH7PzsyvjlYfErKLHm/view?usp=sharing
Share all the resources: Latest Microsoft DP-100 practice questions, latest Microsoft DP-100 pdf dumps. The latest updated Microsoft DP-100 dumps https://www.pass4itsure.com/dp-100.html Study hard and practices a lot. This will help you prepare for the Microsoft DP-100 exam. Good luck!
Discover more from Exampass: Collection of Cisco (CCNA, CCNP, Meraki Solutions Specialist, CCDP...) exam questions and answers from Pass4itsure
Subscribe to get the latest posts sent to your email.